You recently started some Machine Learning projects, got some results, but stumbled on how to evaluate them.
Table Of Content
Everything you see all over the internet (and also on your code output) tells you about these Loss and Accuracy things. How do interpret them? Which one is the correct to evaluate models? This article will explain that, going straight to the point:
Loss
- The value the network is trying to minimize, its the error, the difference between the predicted value and the correct one.
- Let’s consider that the output of the network predicted a 0.8 and it should predict 1.0, the error is then 0.2. The network will change its parameters based on that difference to bring this 0.8 nearly as possible to 1.0.
Accuracy
- How much the network correctly predicts the right class of the input.
- It’s pretty straightforward: if you input 100 images and the network correctly predicts the classes of 86 images, then the Accuracy is 86%.
Time to code!
The best way to learn is by practicing. Let’s train a model using a classic and simple dataset for a problem called Dogs vs Cats, which you can download from here (845 MB). The dataset consists of images of 2 categories, one having only dog images, and the other, just cats. The objective here is to build a classifier that can differentiate between the two image classes.
Use the code below to train the model for some epochs and plot the output on one graph at the end. The training might take a while to finish, depending on your computer. Here I’ll use the Xception[1] network, training over 15 epochs.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | #To instal needed packages: run 'pip3 install matplotlib,keras,h5py,tensorflow' # https://www.floydhub.com/fastai/datasets/cats-vs-dogs/2/train import keras from keras.preprocessing.image import ImageDataGenerator from keras import optimizers, layers, regularizers, Sequential import matplotlib matplotlib.use('TkAgg') from keras.applications.mobilenet_v2 import MobileNetV2 from matplotlib import pyplot as plt #The folder where you images are located images_folder = "/home/jean/cvd" #Declaring and using a ImageDataGenerator to make things simpler while working with images datagen = ImageDataGenerator(validation_split=0.2,) train_dataset = datagen.flow_from_directory(directory= images_folder, class_mode='categorical',subset='training',target_size=(224,224)) validation_dataset = datagen.flow_from_directory(directory= images_folder, class_mode='categorical',subset='validation',target_size=(224,224)) #The networkdeclaration, using a lightweight network model = keras.applications.Xception(weights=None,classes=2, input_shape=(224,224,3)) net = Sequential() net.add(model) net.add(layers.Dense(1500,activity_regularizer=regularizers.l2(l=0.12))) net.add(layers.Dense(2, activation='softmax', name='saida')) #model = MobileNetV2(weights=None, classes=2) net.compile(loss='categorical_crossentropy',optimizer=keras.optimizers.Adam(lr=0.000003),metrics=['acc']) #Training/validation the network history = net.fit_generator(train_dataset, epochs =15, validation_data=validation_dataset, verbose=1) #Uncoment to save your trained model #model.save('model.h5') # Print a plot with the history at the end. plt.subplot(2, 1, 1) plt.plot(history.history['acc']) plt.plot(history.history['val_acc']) plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['Train', 'Validation'], loc='upper left') plt.subplot(2, 1, 2) plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.ylabel('Loss') plt.xlabel('Epoch') plt.legend(['Train', 'Validation'], loc='upper left') plt.savefig('temp.png') print ("Done!") |
Link to the gist of the code above
Training results
Run 1



Run 2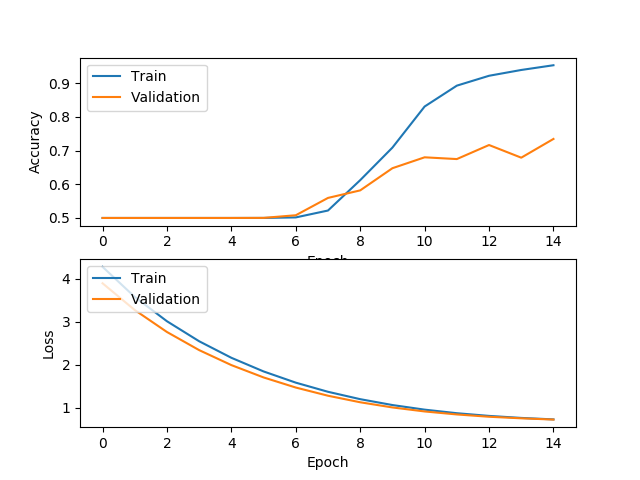



Taking a closer look, the two runs produced the same validation accuracy of 73%. Which one is better, based on the prior Loss/Accuracy explanation?
The second run went a little better than the first one, and because of that, produced a network that predicts more closely the expected values, because of the smaller val_loss (Run 1: 0.7324, Run 2: 0.7266).
This topic goes way further, and with the basic knowledge acquired here, it’s now easier to explore deeper into this. Run more tests, try other datasets, change the code parameters and see how the training/validation process changes.




No Comment! Be the first one.