
Fool your models by doing some Pixel Perturbations
Introduction
This post started as an actual experiment I decided to make a while ago. The experiment was to check how much a well-trained Machine Learning Model could hold its output by slightly changing the visual information of an input image. For us, humans (I’m assuming you are one lol), very small perturbations in the image won’t change our perception of what the image actually is. If you see an image of a dog, you know that it’s a dog in there. Now, if you see the same image, but with some pixels swapped to some random color, It’s still a dog. The point is: our perception won’t change even if a large portion of the image is noisy. It will look weird, for sure, but we can still know what is in there, in most cases.
With that in mind, have you ever thought about how some ML models would react to pixel-level perturbations? Let’s do some experiments.
The Pixel Perturbations
From now on, I’ll call this action of changing a single pixel over an image “RISPP” an acronym for Random Incremental Single Pixel Perturbations. These “RISPPs” are going to be induced on an image by this code snippet:
1 2 3 4 5 6 7 8 9 10 11 | def modify_image(image: cv2.Mat, pixels_per_it = 1) -> cv2.Mat: ''' Modify an image by randomly changing its pixel colors''' h,w,c = image.shape for _ in range(pixels_per_it): random_h = random.randint(0,h - 1) random_w = random.randint(0,w - 1) random_color = [] for _ in range(c): random_color.append(random.randint(0,255)) image[random_h][random_w] = random_color return image |
This will be executed inside a loop, with a network predicting the resulting image right after. Each time this produces an image that increases the distance (loss) from the original prediction, the next iteration image becomes this perturbed one, and the loop continues.
Testing
For this article, and also for simplification purposes, I’ll be using an already available Keras network to run the RISPP algorithm: The MobileNetV3Small with the Imagenet weights and the alpha set to .75.
Let’s start with a goldfish image.

Figure 1 – Goldfish
A forward pass with this image on the MobileNetV3Small produces the following probabilities.
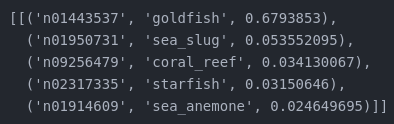
Figure 2 – MobilenetV3Small output probabilities for Figure 1. Not bad, huh?
The prediction is correct. Now let’s change some pixels by running the RISPP loop 500 times.

Figure 3 – Slightly altered image of a goldfish
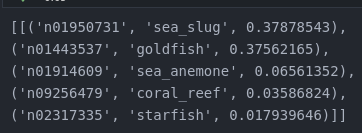
Figure 4 – MobilenetV3Small output probabilities for the slightly altered goldfish image. That’s weird.
In the end, for those 500 Attacks, 66 pixels were modified. Now our goldfish is a… Sea Slug.
For a second, and more aggressive test, let the algorithm do its thing for 5000 tries.

Figure 5 – Goldfish with a lot of perturbed pixels
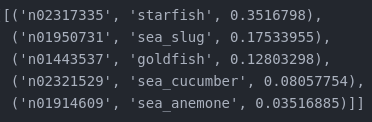
Figure 6 – MobilenetV3Small output probabilities for the heavily altered goldfish image.
For this case, 163 pixels were modified, transforming our Goldfish (former Sea Slug) into a… Starfish.
Here are some interesting results I found while doing this experiment:
Gallery – Click to see more
Considerations about this experiment
That seems almost useless in a production environment, right? Well… actually, small perturbations are not that uncommon in a production environment. To name a few:
- What if your compression algorithm introduces some kind of artifacts
- What if your model is running on faulty equipment (camera, OCT, X-ray)
- What if illegal content is being modified so that it could fool moderation models?
If you are not well prepared for this, that could lead your solution to perform worst than expected.
It is also worth mentioning that this is only one of the possible attacks. There are a bunch of them (even some invisible ones (!)).
The good news is that there are ways to reduce the impact of adversarial attacks like inserting some perturbed images into the training/validation sets (If you wanna know more about some defence mechanisms check Yao Li et al. (2021) as a starting point).
Can I try RISPP at home?
I uploaded a Python notebook to my GitHub so you can try fooling your models. Check it here and have fun breaking your models.
Relevant links
This is already a well-documented field, that started around 2015 and keeps growing stronger since then. The research in this domain keeps pushing ML models to their limits, both for attack or/and defense.
For additional info, check those papers that were also used to fundament this experiment: Haotian Zhang, XuMa (2022), Hong Wang et al. (2021), Atiye Sadat Hashemi & Saeed Mozaffari (2021), Kevin Eykholt et al. (2018), Xiaoshuang Shi et al.(2022), Jiawei Su et. al (2017).
Have fun with your projects!
If this post helped you, please consider buying me a coffee 🙂