Training Machine learning models depends a lot on your general organization.
Sometimes, changing a single parameter is the difference between a useless model and a very good one. So, if you are working with an ML model that needs to be feasible in real life, a lot of tunning needs to be done. Filtering the good parameters and changing the ones that make your training/validation scores worst is essential.
For doing that in an optimized way you’ll need something to track all the information used to tune the model. Pen and paper or even spreadsheets just do not do a satisfactory job here. Those methods depend on writing down percentages, pieces of code, results, and other relevant info every time something in your model changes.
Automate your experiments
Sacred is a tool to automate all important stuff with a few lines of code. The tool definition accordingly to its GitHub page:
Sacred is a tool to help you configure, organize, log and reproduce experiments. It is designed to do all the tedious overhead work that you need to do around your actual experiment in order to:
- Keep track of all the parameters of your experiment
- Easily run your experiment for different settings
- Save configurations for individual runs in a database
- Reproduce your results
That sounds amazing, right? Because it is. Storing everything automagically! And when it runs together with a frontend such as Omniboard, it becomes even more accessible. An example of what Sacred/Ominiboard looks like can be seen in Figure 1.
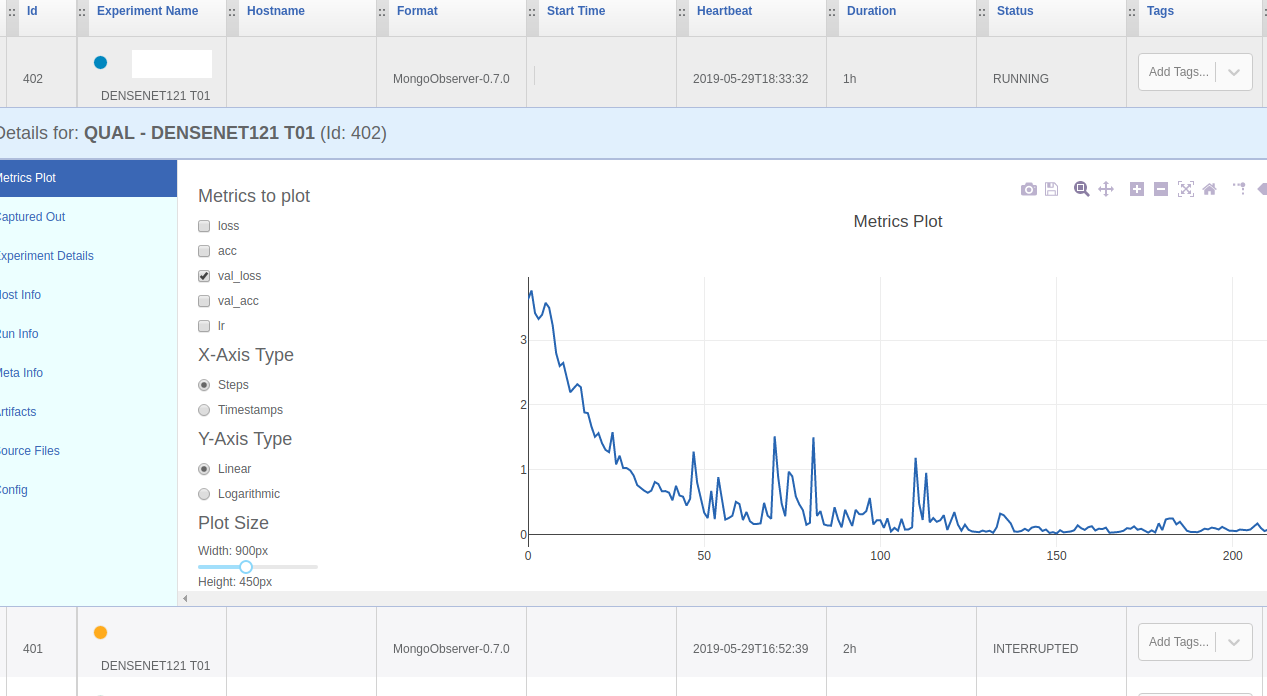
Figure 1 – Omniboard front end
Installation
Python’s pip, apt-get, and npm are capable of doing everything. Run the following commands on your terminal:
1 2 3 4 5 6 7 8 9 | pip install numpy, pymongo pip install sacred sudo apt-get install nodejs sudo apt-get install npm npm install -g omniboard |
To start, run omniboard on Terminal, and it will connect to mongodb://localhost/sacred
on port 9000 by default. Now it should be accessible on your browser through the YOURIP:9000 address.
How to use
You need to add some lines to your code in order to make Sacred store and show the desired info. Please note that here I gonna use Keras with a Tensorflow backend during the training step.
- First: add the libraries:
1 2 3 | from sacred import Experiment from sacred.observers import MongoObserver from sacred.utils import apply_backspaces_and_linefeeds |
- Add a callback to update our results each time an epoch ends. There are a lot of options you can use, let’s stick here with validation/training accuracies, losses, and the learning rate.
1 2 3 4 5 6 7 8 9 10 11 12 13 | class LogMetrics(Callback): def on_epoch_end(self, _, logs={}): my_metrics(logs=logs) @ex.capture def my_metrics(_run, logs): _run.log_scalar("loss", float(logs.get('loss'))) _run.log_scalar("acc", float(logs.get('acc'))) _run.log_scalar("val_loss", float(logs.get('val_loss'))) _run.log_scalar("val_acc", float(logs.get('val_acc'))) _run.log_scalar("lr", float(logs.get('lr'))) _run.result = float(logs.get('val_loss')) |
- Insert your main code inside a function called run() with the @ex.automain decorator, as shown below:
1 2 3 4 5 6 7 8 9 | @ex.automain def run(): # YOUR CODE # (....) history = model.fit_generator(train, epochs = 150, validation_data=validation, verbose=1, use_multiprocessing=True, workers=8,steps_per_epoch=(len(train)), validation_steps = len(val idation), callbacks=[LogMetrics()]) |
Now, each time you start training the network, everything you configured will be stored as a run on Omniboard by now, just showing a graph. The icing on the cake is that by using the @ex.config decorator, is possible to store the values of the variables.:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | @ex.config def cfg(): batch = 16 val_batch = 1 number_epochs = 120 steps_epoch = 100 image_size = (448, 448) alpha_value = 1.4 out_pooling = 'avg' output_activation = 'softmax' model_loss = 'categorical_crossentropy' optimizer = 'Adam' non_trainable_layers =0# 150#150 learning_rate = 0.0001 validation_split = 0.3 dropout_rate = 0.5 number_of_augmented_images = 7 regularizer_rate = 0.09 |
Use all the variables inside the cfg()function as parameters to run()
implemented above. With the shown variables, our run() now became:
1 2 3 4 | @ex.automain def run(batch, val_batch, number_epochs, steps_epoch, image_size, alpha_value, out_pooling, output_activation, model_loss, optimizer, learning_rate, non_trainable_layers,validation_split ,dropout_rate, number_of_augmented_images, regularizer_rate): |
Easy, right? Sacred is a really good tool, and you will be grateful to not worry about this anymore. They can do a lot of additional things, so take a look at the Sacred and Omniboard documentations.